 X-LLM: Connecting multiple single-modal encoders and a large language model.
X-LLM: Connecting multiple single-modal encoders and a large language model.
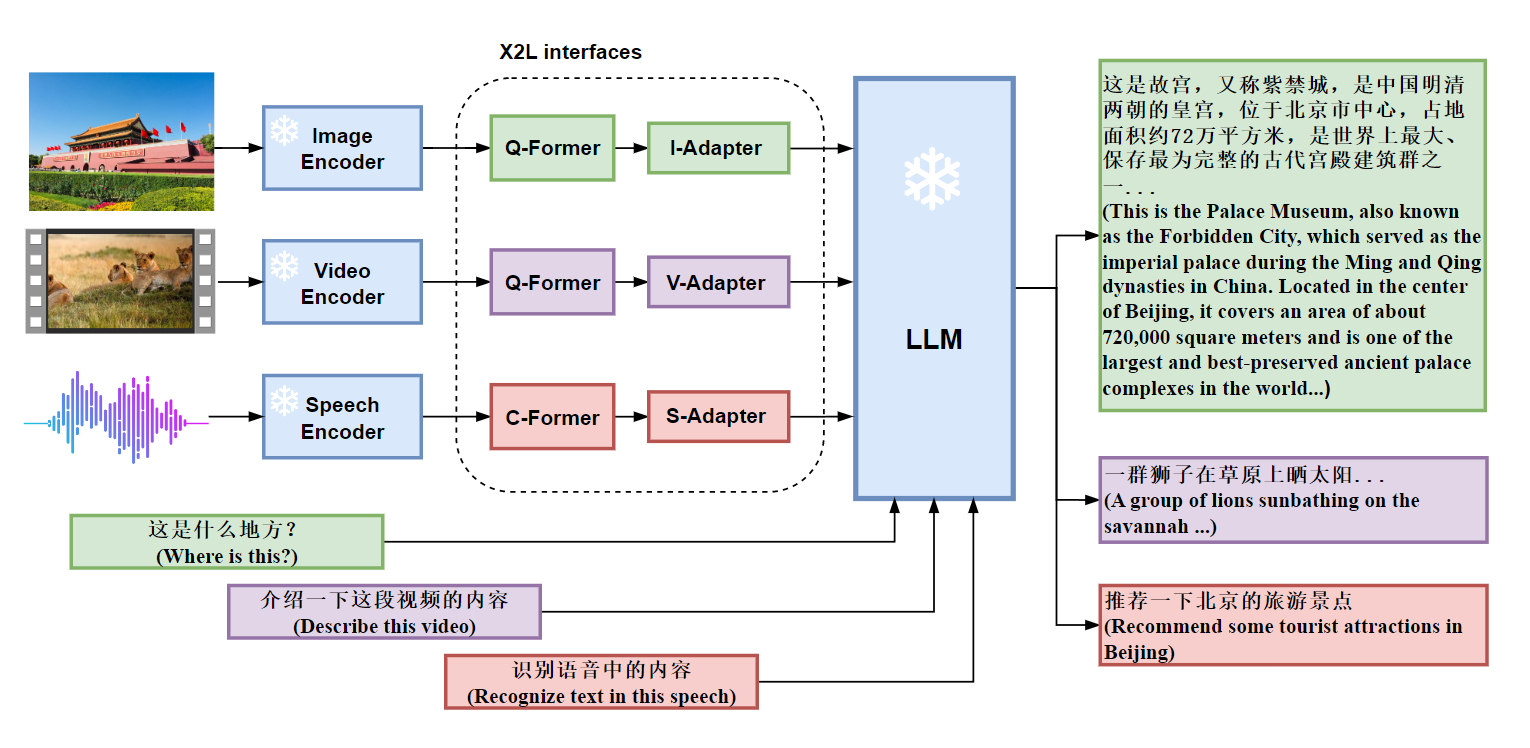
X-LLM connects multiple pre-trained single-modal encoders (such as ViT-g visual encoder) and large language model ChatGLM, using X2L interfaces. We consider a three-stage training procedure:
- Stage 1: Converting Multimodal Information. Convert multimodal information into foreign languages through X2L interfaces, only X2L interfaces are updated
- Stage 2: Aligning X2L Representations with the LLM. Inject foreign languages into LLM, only X2L interfaces are updated.
- Stage 3: Integrating Multiple Modalities. Integrating multi-modalities, only the adapters in X2L interfaces are updated.
 Performance
Performance
 Multimodal Chat: Towards building multimodal GPT-4 level chatbot
Multimodal Chat: Towards building multimodal GPT-4 level chatbot
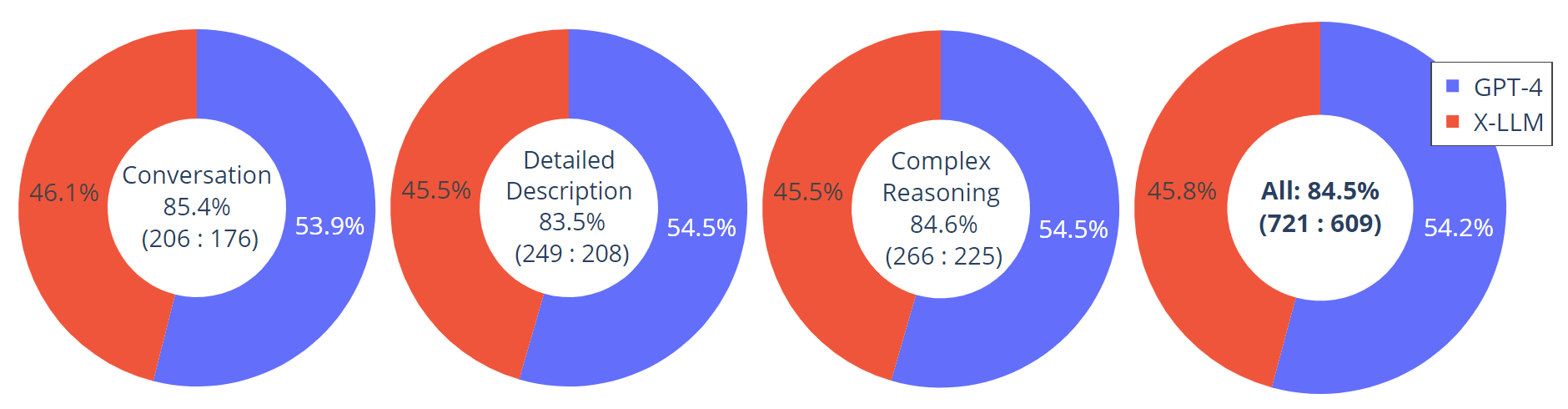
An evaluation dataset with 30 unseen images is constructed: each image is assocaited with three types of instructions: conversation, detailed description and complex reasoning. This leads to 90 new language-image instructions, on which we test X-LLM and GPT-4, and use ChatGPT to rate their responses from score 1 to 10. The summed score and relative score per type is reported. Overall, X-LLM achieves 84.5% relative score compared with GPT-4, indicating the effectinvess of the proposed method in multimodal settings.
Examples on Visual Instruction Following
Visual Chat on two Chinese characteristic examples


BibTeX
@article{chen2023x,
title={X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages},
author={Chen, Feilong and Han, Minglun and Zhao, Haozhi and Zhang, Qingyang and Shi, Jing and Xu, Shuang and Xu, Bo},
journal={arXiv preprint arXiv:2305.04160},
year={2023}
}
Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the ChatGLM team for giving us access to their models, and open-source projects.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of ViT-g, BLIP2, ChatGLM, and ChatGPT. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.